This is a follow up to https://colorblindprogramming.com/round-probabilities-before. Last year I stopped after discovering that the only correct way to calculate the odds is to look at the probability trees. This year I took this one step forward and created a script that would calculate the correct probabilities. I intend to reuse this script for the future draws, and a year it’s a long time for my memory so I am adding some notes here.
The incorrect approach: the big-bowl
The first approach last year was to calculate all the possible pairs, eliminate the invalid ones and then calculate the associated percentages for each pair. In hindsight, this approach was obviously wrong, because it doesn’t replicate the actual draw. This approach would only be accurate if the draw consisted of a single draw – from a very big bowl of all the valid options. This is obviously not how the actual draw works, so even if the final numbers were pretty close to the correct ones, it was not the correct approach.
The correct approach, using conditional probabilities
The correct way to look at this is by understanding that we are talking about dependent events. Each draw depends on the actual result of the previous draw. It’s identical to this process, beautifully explained on MathIsFun.com:
So how do we actually do it?
There are two approaches: The first one is a bit more complicated and implies creating the tree above for the 16 teams and 16 steps (each team pick is a step). It has the advantage of producing accurate results, but it’s a bit more difficult to implement. The second one consists of simulating the draw process and repeating it a lot of times. I found this approach easier, here is the pseudo-code of the draw process:
for each unseeded team
if there is a mandatory draw (starting from the 5th unseeded team)
then automatically create the pair and add it to the draw
otherwise, pick a random unseeded team
get the list of available seeded teams
randomly pick a seeded team from the list above
add pair to the draw
end
Repeating this process a few millions of times would lead to millions of possible draws, and based on that we can calculate the percentages.
But there are 2 catches: 1. Checking both sides of the draw. Have a look at the step 2 above, checking if there is a mandatory draw: let’s say you are left with 4 unseeded teams and 4 seeded teams. It’s not enough to look at the unseeded teams options, you also need to look the other way around. Example: Unseeded teams: Liverpool, United, Shalke, Lyon Seeded teams: PSG, City, Real, Barcelona Liverpool has 2 options, United 3, Shalke 4 and Lyon 2. But if you randomly pick Shalke and you pair it with any of PSG, Real or Barcelona, then you leave an impossible draw for City (which cannot be drawn against any of the 3 English teams left). So the solution is to count the number of options for both unseeded and seeded teams. If there is a single option, pick it.
2. Go back if needed. Even with the above safety mechanism in place things can still go wrong. Example: Unseeded teams: Roma, Liverpool, Shalke, Lyon Seeded teams: Porto, Barcelona, PSG, City Options for the unseeded teams: Rome -4, Liverpool -2, Shalke -4, Lyon -2. Options for the seeded teams: Porto -3, Barcelona -4, PSG -2, City -2. The safety mechanism above (counting the number of options for both seeded and unseeded teams) tells us that everything is fine. So we go ahead and pair Rome with Porto. We are now left with: Unseeded: Liverpool -1, Shalke -3, Lyon -1 Seeded: Barcelona -3, PSG -1, City -1. The problem is that both PSG and City have an option, and that option is Shalke. So this leads to an impossible draw, so the solution in this case is to go back one step and pick another draw instead of Roma v Porto. According to my calculations this could happen in about 0.4% of cases, and I am really curious how UEFA would handle it if it happened on stage. In the scenario above, if Roma was selected as unseeded team, I expect that the computer will only allow PSG and City to be one of the seeded teams, but I am really curious to hear the hosts explanation about this constraint (since both Porto and Barcelona are, at first sight, also valid options for Roma) 🙂
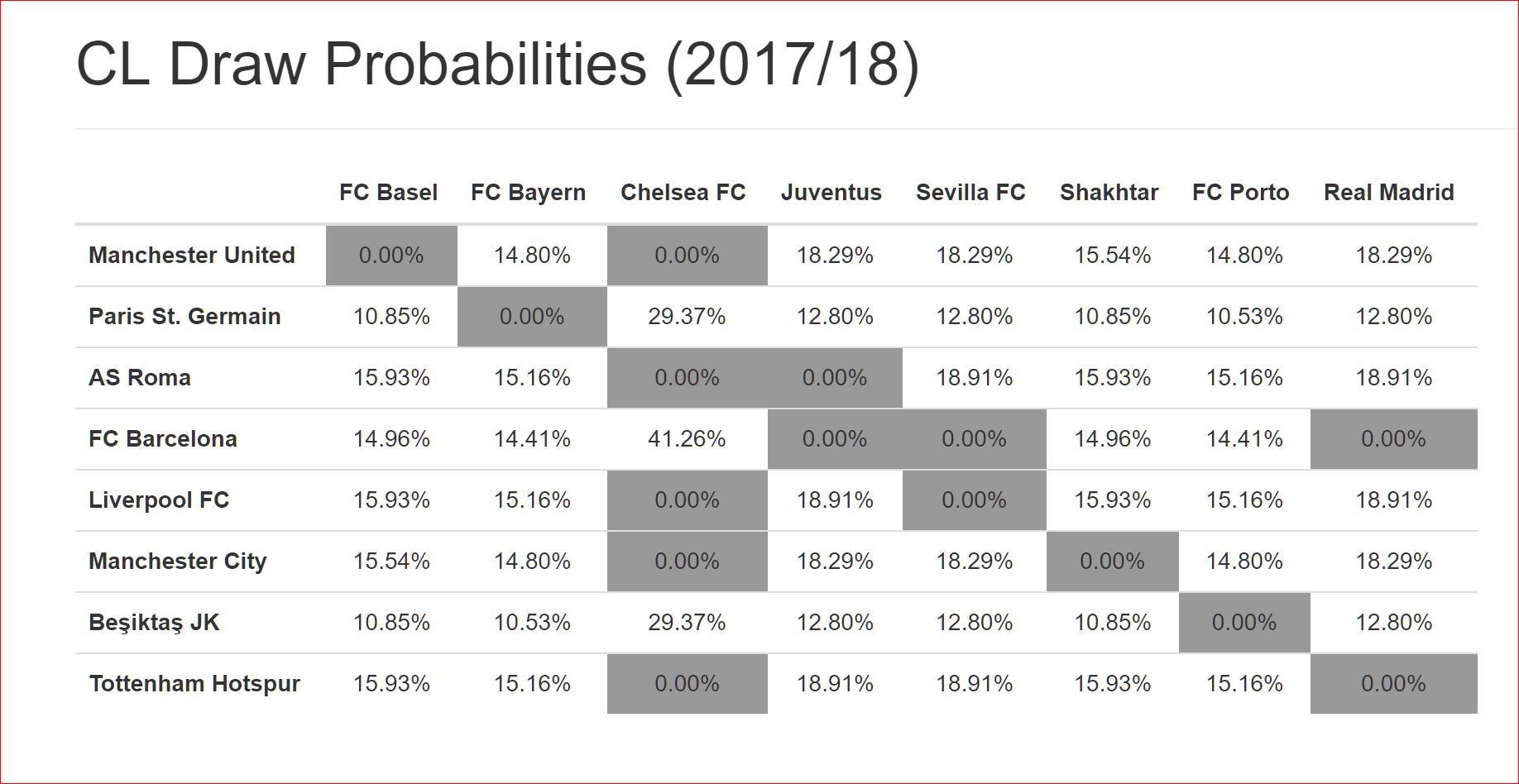
Using the algorithm above, I ran the simulation 2 million times. These are the results:
Checking the results
The nice thing about being both a geek and a football lover is that you get to know smart persons at the intersection of science and football. Two of them are Julien Guyon and Emmanuel Syrmoudis. They also spent time thinking about this topic. Julien came up with a great explanation of the draw process and probabilities, while Emmanuel went one step forward and actually created an interactive draw simulator.
My results come pretty close to theirs, so I’m quite confident that my method is decent enough. I plan to reuse it again next year and, perhaps, also try to create the actual probability tree to get the exact percentages.
A post where football meets science again 🙂 This time, it’s about probabilities.
On 11 December 2017 the UEFA Champions League draw will take place. There will be 16 teams which will be drawn one against each other. There are some restrictions:
– 8 teams are seeded, the other 8 are unseeded. A seeded team can only be drawn against an unseeded team
– teams from the same country cannot be drawn against each other
– teams that already met in the previous round cannot be drawn against each other
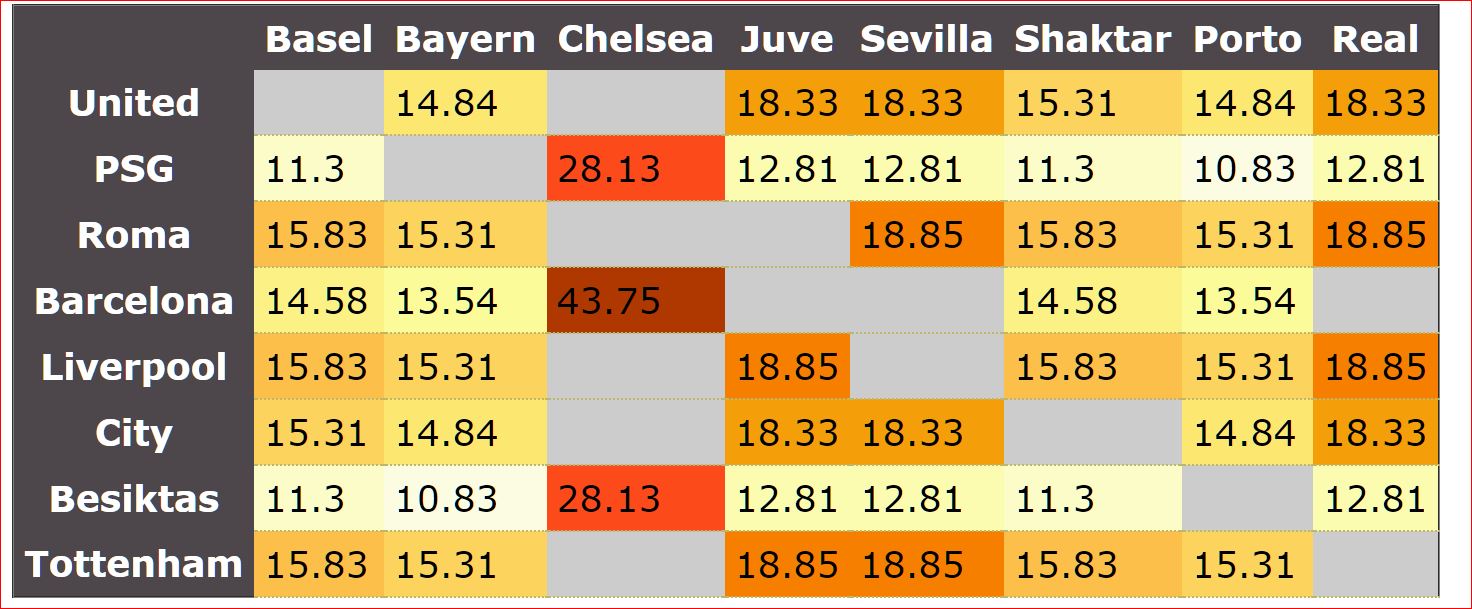
Based on these elements, I wanted to calculate the associated probabilities, or other words to reveal the question marks in the matrix below:
(first column – seeded teams, first line – unseeded teams, greyed cells – teams cannot be drawn).
Try 1: Thursday night
I make a quick PHP script to calculate all the possible permutations (8!=40320), then I eliminate the invalid options and find that only 4238 permutations are possible. I count all the possible team pairings as below:
I calculate the associated percentage for each pair (example for Liverpool-Real it’s 799 out of 4238=18.85%) and, after half an hour spent choosing a color scheme, I put everything in the matrix:
Then I realize that the numbers are slightly different from the ones circulated on social media:
Try 2: the entire weekend
I get a very nice explanation on Twitter from the author of the tool above:
You have to consider all possible ways this pairing can be drawn. Take a look and sorry for the handwriting: pic.twitter.com/9bMJD3aNWG
Then I start to realize that my approach was incorrect.
In fact, my numbers were only valid if the draw process consisted of a single step – somebody picking up a random number from 1 to 4238 and then showing up the 8 pairings behind that number.
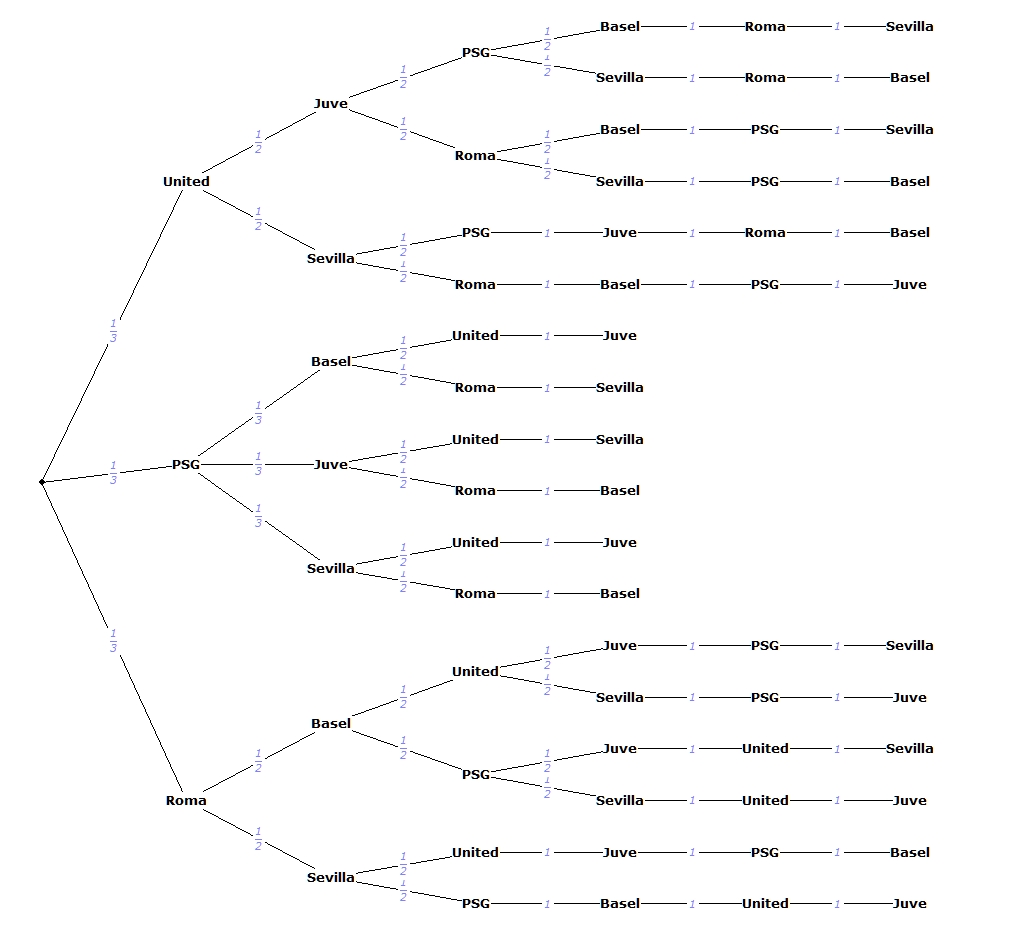
But in fact, the draw process consist of 8 steps or 8 events, each one depending on the previous one. We speak in this case of conditional probabilities, which are represented using a probability tree. The probability tree for a subset of 6 teams looks like this:
And indeed, the tree simulates the real draw process and reveals the same numbers as the ‘official’ ones:
I finally get it, @e_mi_nga ! 💡 It's because the events are dependent => conditional probabilities => tree diagrams. The 33% percentage would apply if somebody would randomly pick one of the 3 possible pairings. But the draw consists of 3 dependent events. Thank you all! pic.twitter.com/pRmLS1hwPw
Since the draw is in less than 12 hours, I have no time to make another script that generates the full tree (that would also be too big to put in a picture). But I trust the numbers from https://eminga.github.io/cldraw/ are correct 🙂