“Never trust summary statistics alone; always visualize your data”
Written on 8 November 2020, 12:46pm
Tagged with: science, statistics
Recently, Alberto Cairo created the Datasaurus dataset which urges people to “never trust summary statistics alone; always visualize your data”, since, while the data exhibits normal seeming statistics, plotting the data reveals a picture of a dinosaur. These 13 datasets (the Datasaurus, plus 12 others) each have the same summary statistics (x/y mean, x/y standard deviation, and Pearson’s correlation) to two decimal places, while being drastically different in appearance.
https://www.autodesk.com/research/publications/same-stats-different-graphs

Below I try to understand the highlighted concepts.
Mean and deviation
The concepts of population, sample, mean, variance and standard deviation (SD):

Same mean but different variance and SD:

Examples of means and SDs from mathisfun.com:
A population of dogs, with the heights at the shoulders of 600mm, 470mm, 170mm, 430mm and 300mm. The mean (average height) is 394mm
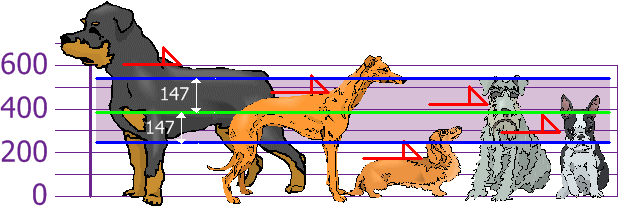
The variance is 21704mm, and the standard deviation is 147mm:

Population vs sample
However if the data is just a sample of the population, then the variance and standard deviation change (see the cheat sheet, with the difference between sigma and s):

The 68–95–99.7 rule
For the normal distribution (Gauss/bell curve), approx. 68% of the values are within 1 standard deviation from the mean, 95% are within 2 SDs and 99.7% are within 3 SDs:

Examples:


The correlation coefficient (or Pearson’s correlation)



Coefficient of determination
The square of the correlation coefficient is the coefficient of determination: R2 or R-squared.
R2 is a statistic that will give some information about how well a model fits a set of observations. In regression, the R2 coefficient of determination is a statistical measure of how well the regression predictions approximate the real data points. An R2 of 1 indicates that the regression predictions perfectly fit the data.
Simply put, the R-squared indicate the percentage of data points falling on the regression line.


Read more:
Written by Dorin Moise (Published articles: 294)
Comments (1)